ArxivRollBench:你的模型在"作弊"吗?
1. 背景:Benchmark的信任危机
LLM的benchmark越来越多,分数越来越高。但有一个根本问题:这些分数有多少是真实的模型能力,有多少是因为模型在训练时"见过"了测试题?
这就是所谓的benchmark contamination(基准污染)。现有的benchmark都是静态的——题目是固定的,只要时间够长,总会被模型"记住"。
2. 我们的方案:ArxivRollBench
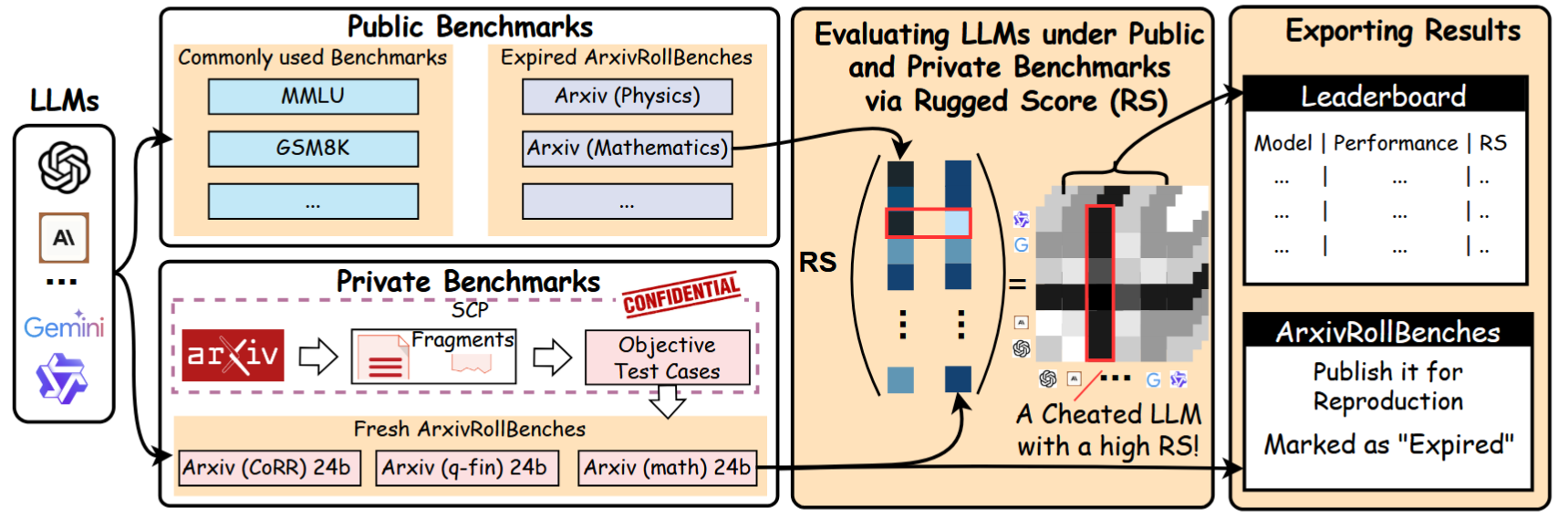
借鉴密码学中One-Time-Pad(一次性密码本)的思想,我们设计了一个动态benchmark。
ArxivRollBench每天自动从最新arXiv论文中提取内容,生成全新的测试用例。因为论文是当天新发布的,模型不可能在训练时见过——所以测试结果不受contamination影响。
我们还提出了一个量化"作弊程度"的evaluation framework——你可以精确衡量一个模型在"见过题"和"没见过题"两种情况下的表现差异。
3. Leaderboard
4. 论文信息
- 标题: How Much Do Large Language Model Cheat on Evaluation? Benchmarking Overestimation under the One-Time-Pad-Based Framework
- 作者: Zi Liang, Liantong Yu, Shiyu Zhang, Qingqing Ye, Haibo Hu
- 状态: AAAI 2026
- 代码: https://github.com/liangzid/ArxivRoll
- 网站: https://arxivroll.moreoverai.com