ArxivRollBench: Is Your Model Cheating on the Test?
1. Background: The Trust Crisis of Benchmarks
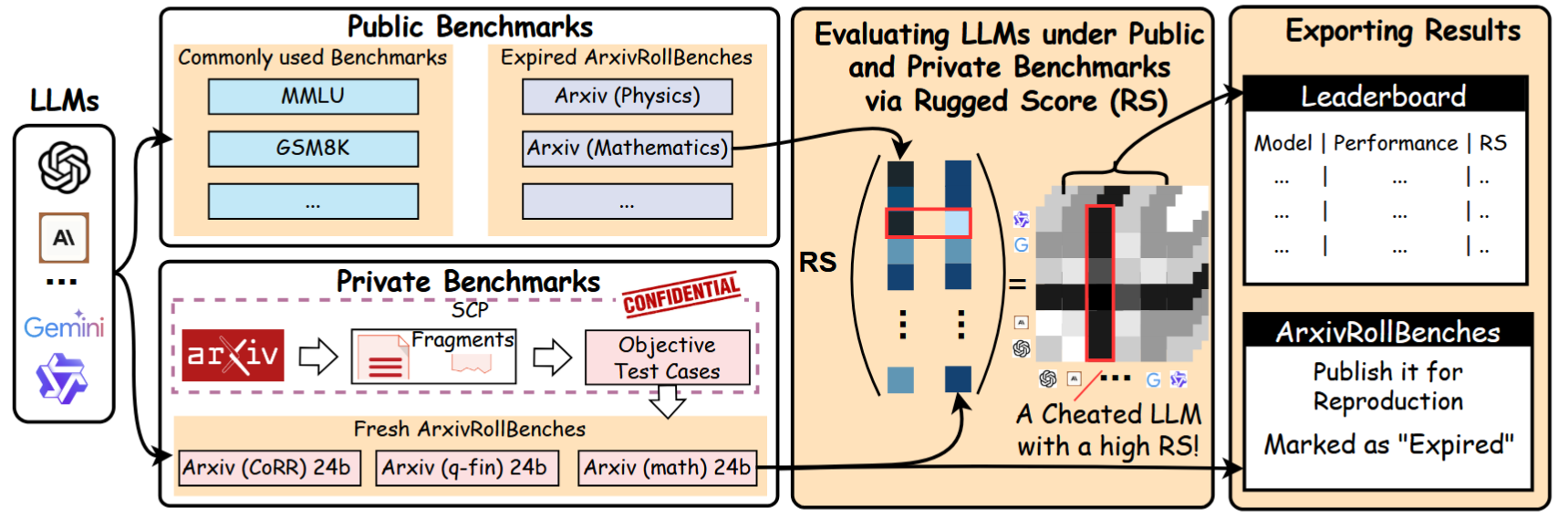
There are more and more LLM benchmarks, and scores keep going up. But here is the fundamental problem: how much of that score reflects real capability, and how much is because the model "saw" the test questions during training?
This is benchmark contamination. Existing benchmarks are static—the questions are fixed. Given enough time, models will memorize them.
2. Our Solution: ArxivRollBench
Drawing inspiration from the One-Time-Pad in cryptography, we designed a dynamic benchmark.
ArxivRollBench automatically extracts content from newly published arXiv papers every day and generates fresh test cases. Since the papers were published that day, the model cannot possibly have seen them during training—so test results are contamination-free.
We also proposed a quantitative "cheating ratio" evaluation framework—you can precisely measure the performance gap between "seen" and "unseen" test conditions for any model.
3. Leaderboard
The leaderboard is at: https://arxivroll.moreoverai.com. I update it every six months. Already we see some interesting patterns—certain models that score highly on static benchmarks drop significantly on ArxivRollBench.
4. Paper Info
- Title: How Much Do Large Language Model Cheat on Evaluation? Benchmarking Overestimation under the One-Time-Pad-Based Framework
- Authors: Zi Liang, Liantong Yu, Shiyu Zhang, Qingqing Ye, Haibo Hu
- Status: AAAI 2026
- Code: https://github.com/liangzid/ArxivRoll
- Website: https://arxivroll.moreoverai.com