Prompt Leakage:你的系统提示词,藏不住的
1. 背景:GPTs火了之后的隐忧
OpenAI推出GPTs之后,人人都能创建自己的定制化ChatGPT。常见的做法是把核心逻辑、角色设定、甚至商业机密写在system prompt里。大家觉得——"模型本身有alignment保护,prompt应该不会被泄露吧?"
我们证明了:会,而且很容易。
2. 三个核心问题
我们系统性地研究了三个问题:
- Alignment能防住prompt extraction吗? 答案:基本不能。无论是RLHF还是Constitutional AI,都挡不住精心构造的extraction query。
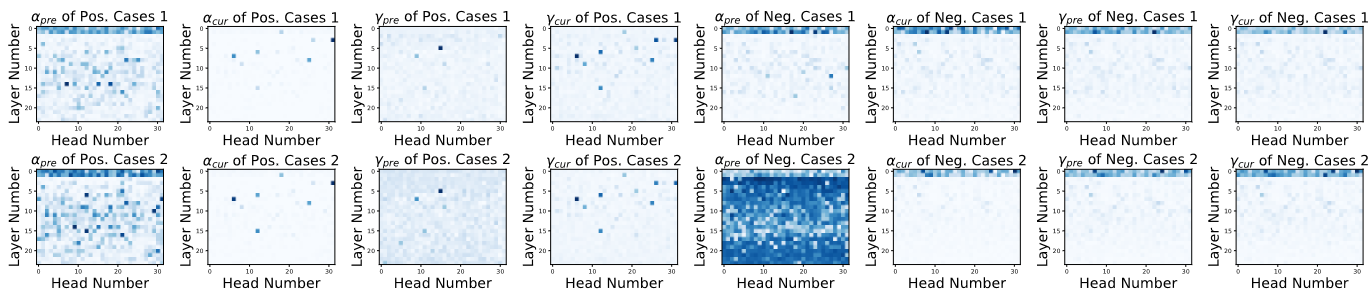
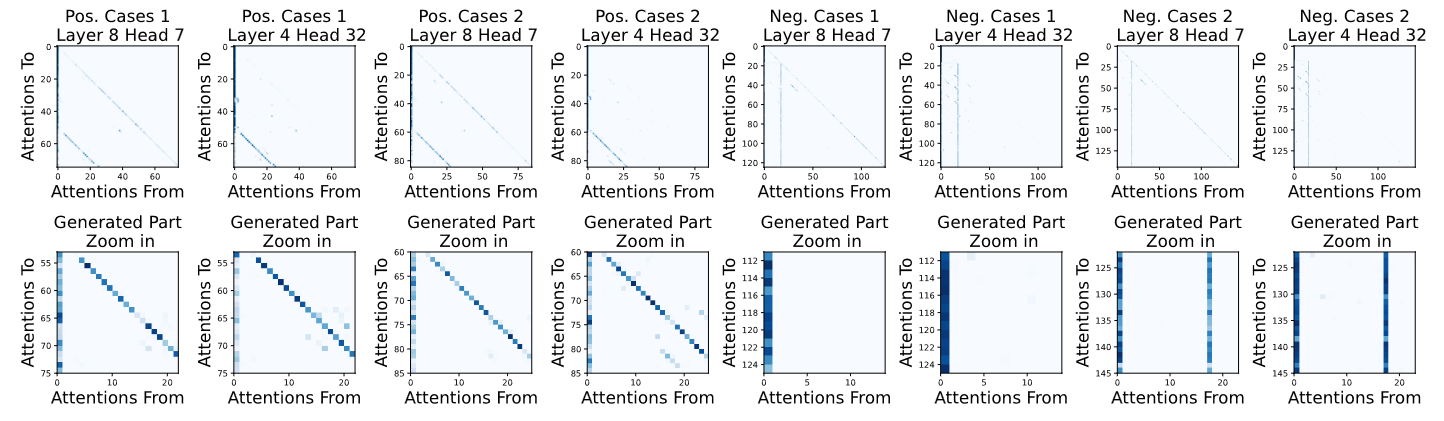
- 模型是怎么泄露prompt的? 我们提出了两个假设:(a) "注意力残留"——prompt token在生成过程中持续影响attention分布;(b) "语义惯性"——模型在生成过程中保持了对prompt语义的忠实性。实验验证了两个假设都存在。
- 哪些因素影响泄露程度? Prompt越长越容易泄露,复杂度越高越容易泄露,模型越大反而越容易泄露(反直觉但合理——大模型"记住"prompt的能力更强)。
3. 防御策略
基于这些发现,我们提出了几种低成本防御:prompt压缩、动态prompt注入、以及基于注意力的检测机制。不需要重新训练模型。
4. 论文信息
- 标题: Why Are My Prompts Leaked? Unraveling Prompt Extraction Threats in Customized Large Language Models
- 作者: Zi Liang, Haibo Hu, Qingqing Ye, Yaxin Xiao, Haoyang Li
- 状态: Preprint
- 论文: https://arxiv.org/abs/2408.02416