Prompt Leakage: Your System Prompts Cannot Hide
1. Background: The Hidden Risk Behind GPTs
When OpenAI launched GPTs, anyone could create a customized ChatGPT. The common practice is to embed core logic, role definitions, and even trade secrets in the system prompt. People assumed: "The model has alignment protection—my prompt should be safe, right?"
We showed: wrong. It leaks. Easily.
2. Three Core Questions
We systematically investigated three questions:
- Can alignment defend against prompt extraction? Short answer: barely. Neither RLHF nor Constitutional AI stops well-crafted extraction queries.
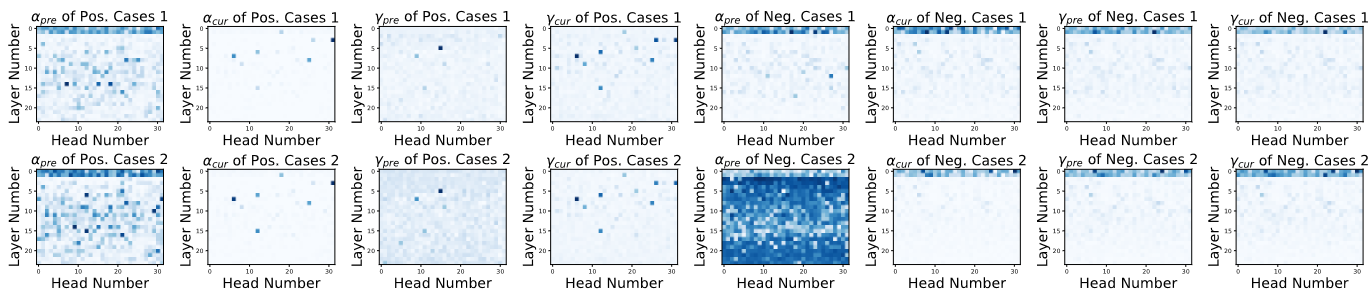
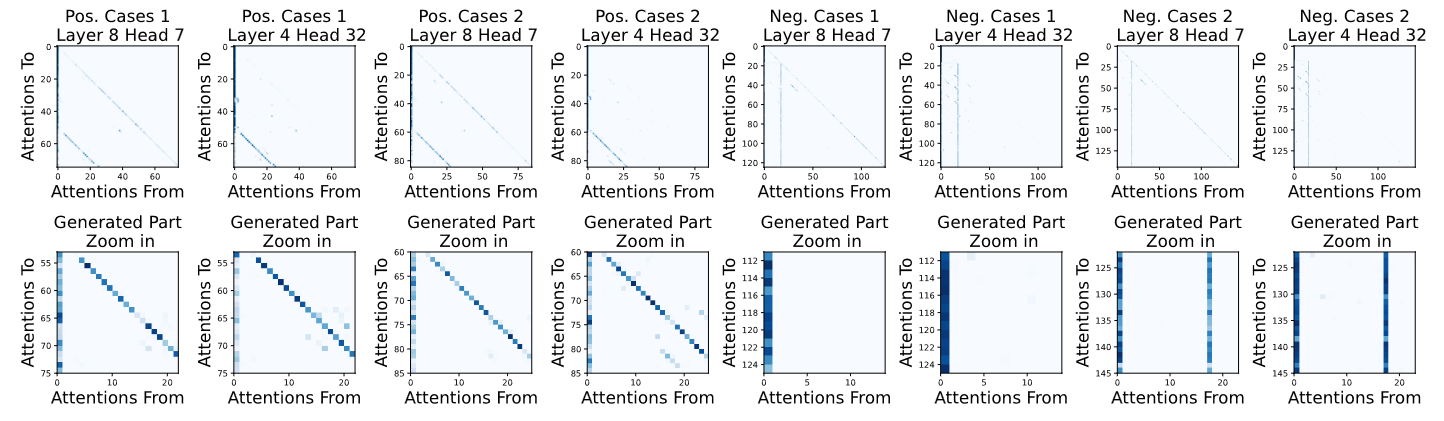
- How do models leak prompts? We proposed two hypotheses: (a) "Attention Residual"—prompt tokens persistently influence attention distributions during generation; (b) "Semantic Inertia"—the model maintains semantic fidelity to the prompt throughout generation. Both were experimentally validated.
- What factors affect leakage severity? Longer prompts leak more. More complex prompts leak more. And counterintuitively, larger models leak /more/—because they are better at "remembering" the prompt.
3. Defense Strategies
Based on these findings, we proposed several low-cost defenses: prompt compression, dynamic prompt injection, and attention-based detection mechanisms. No model retraining required.
4. Paper Info
- Title: Why Are My Prompts Leaked? Unraveling Prompt Extraction Threats in Customized Large Language Models
- Authors: Zi Liang, Haibo Hu, Qingqing Ye, Yaxin Xiao, Haoyang Li
- Status: Preprint
- Paper: https://arxiv.org/abs/2408.02416