LoRD:怎么"偷"走一个大语言模型?
1. 背景:模型窃取是真实威胁
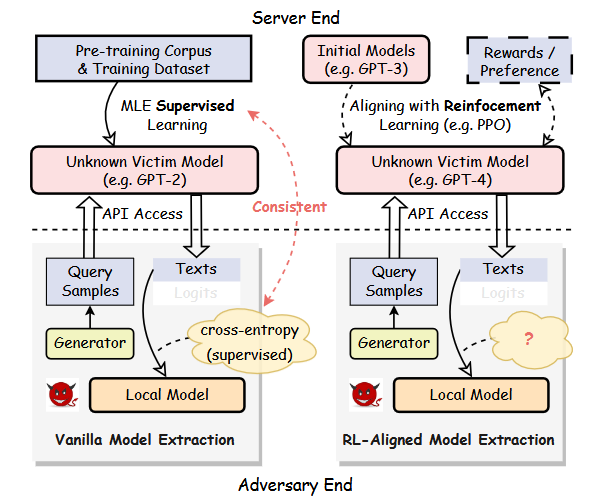
Model extraction(模型窃取)攻击的核心思想很简单:攻击者通过反复查询你的LLM API,收集输入-输出对,然后用这些数据训练一个"替代模型"来复制你的模型能力。
这不仅仅是学术上的好奇。如果你的LLM API是公开的(比如按token收费),攻击者完全可以用很低的成本"偷"走你的模型,然后自己部署,不再付钱。
2. 问题:MLE不够用了
传统的extraction方法用交叉熵(MLE)做蒸馏。但我们发现了一个问题:如果目标模型是用RL训过的(比如RLHF),MLE就不太行了。原因是RL训练会改变输出的分布特性,而MLE假设的分布和实际分布不匹配。
3. 我们的方法:LoRD
LoRD(Locality Reinforced Distillation)是一种新的RL-based extraction方法。核心思想是利用目标模型输出的"局部结构"——即在相近输入上,目标模型的输出之间存在的关联——来引导替代模型的学习。
实验表明,LoRD在提取效率(需要更少的查询)和提取质量(替代模型更接近目标模型)上都显著优于MLE baseline。更有意思的是,LoRD天然对某些watermark防御有一定的抵抗力。
4. 论文信息
- 标题: "Yes, My LoRD." Guiding Language Model Extraction with Locality Reinforced Distillation
- 作者: Zi Liang, Qingqing Ye, Yanyun Wang, Sen Zhang, Yaxin Xiao, Ronghua Li, Jianliang Xu, Haibo Hu
- 状态: ACL 2025 Main
- 代码: https://github.com/liangzid/LoRD-MEA