LoRD: How to Steal a Large Language Model
1. Background: Model Extraction Is a Real Threat
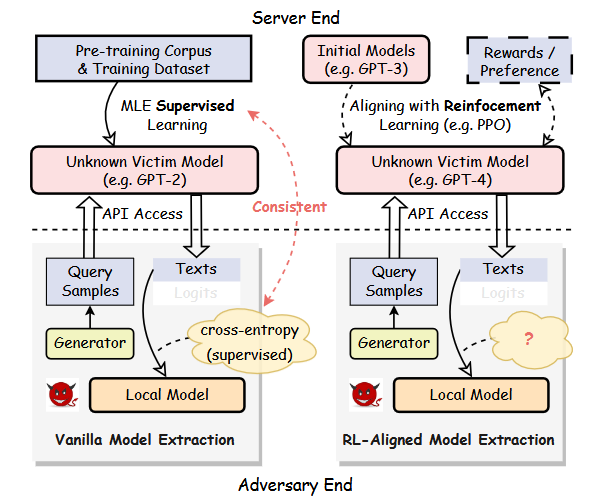
Model extraction is simple in concept: the adversary repeatedly queries your LLM API, collects input-output pairs, and trains a "substitute model" to replicate your model's capabilities.
This is not just academic curiosity. If your LLM API is public (e.g., pay-per-token), an adversary can steal your model at low cost, deploy it independently, and stop paying you.
2. The Problem: MLE Falls Short
Traditional extraction methods use cross-entropy (MLE) for distillation. But we found a problem: if the target model was trained with RL (e.g., RLHF), MLE does not work well. RL training shifts the output distribution, and the MLE assumption no longer matches.
3. Our Method: LoRD
LoRD (Locality Reinforced Distillation) is a new RL-based extraction method. The core idea is to exploit the "local structure" of the target model's outputs—the relationships between outputs on similar inputs—to guide the substitute model's learning.
Experiments show that LoRD significantly outperforms MLE baselines in both extraction efficiency (fewer queries needed) and extraction quality (substitute model closer to target). Interestingly, LoRD also shows natural resistance to certain watermark-based defenses.
4. Paper Info
- Title: "Yes, My LoRD." Guiding Language Model Extraction with Locality Reinforced Distillation
- Authors: Zi Liang, Qingqing Ye, Yanyun Wang, Sen Zhang, Yaxin Xiao, Ronghua Li, Jianliang Xu, Haibo Hu
- Status: ACL 2025 Main
- Code: https://github.com/liangzid/LoRD-MEA