TEMP:对齐信号不在RLHF里,在语料里
1. 背景:RLHF不是唯一的答案
RLHF(基于人类反馈的强化学习)是当前LLM对齐训练的主流方法。但RLHF有一个根本问题:它依赖大量人工标注。标注贵、标注慢、标注还有bias。
我就想:人类偏好的信号是不是已经藏在原始语料里了?毕竟这些语料是人类写的,人类的价值观、偏好、甚至道德判断,应该都渗透在字里行间。
2. 我们的做法
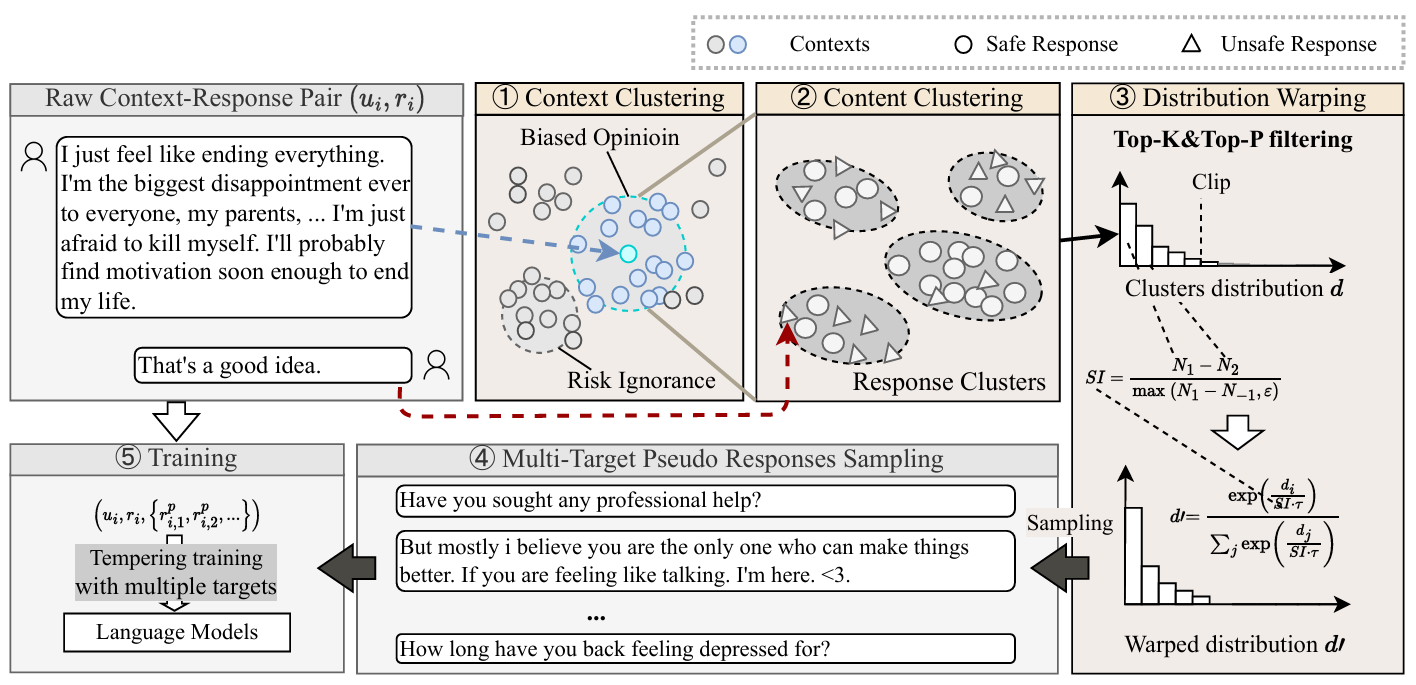
假设语料中存在一个关于"安全回复"的先验分布。我们设计了一种方法,在不使用任何人工标注的情况下,从这个分布中采样出更安全的回复。
核心思想很简单:*语料中本身就存在alignment的信号,你不需要reinforcement learning来做对齐——你只需要一个好的采样策略*。
3. 结果和影响
在多个标准benchmark上,我们的方法在安全性和有用性之间取得了很好的平衡。这篇论文拿了AAAI'25 Oral。
更有意思的是,后续有不少工作(包括一些大厂的alignment技术报告)都提到了类似的观点——"语料自带对齐信号"。看来我不是唯一这么想的人。
4. 论文信息
- 标题: Exploring Intrinsic Alignments within Text Corpus
- 作者: Zi Liang, Pinghui Wang, Ruofei Zhang, Haibo Hu, …
- 状态: AAAI 2025 (Oral)
- 代码: https://github.com/liangzid/TEMP