TEMP: Alignment Signals Are in the Data, Not in RLHF
1. Background: RLHF Is Not the Only Answer
RLHF (Reinforcement Learning from Human Feedback) is the dominant approach to LLM alignment. But it has a fundamental problem: it relies on massive human annotation. Annotation is expensive, slow, and biased.
I wondered: are human preference signals already latent in the raw text corpus? After all, the corpus is written by humans. Human values, preferences, and even moral judgments should be embedded in the text.
2. Our Approach
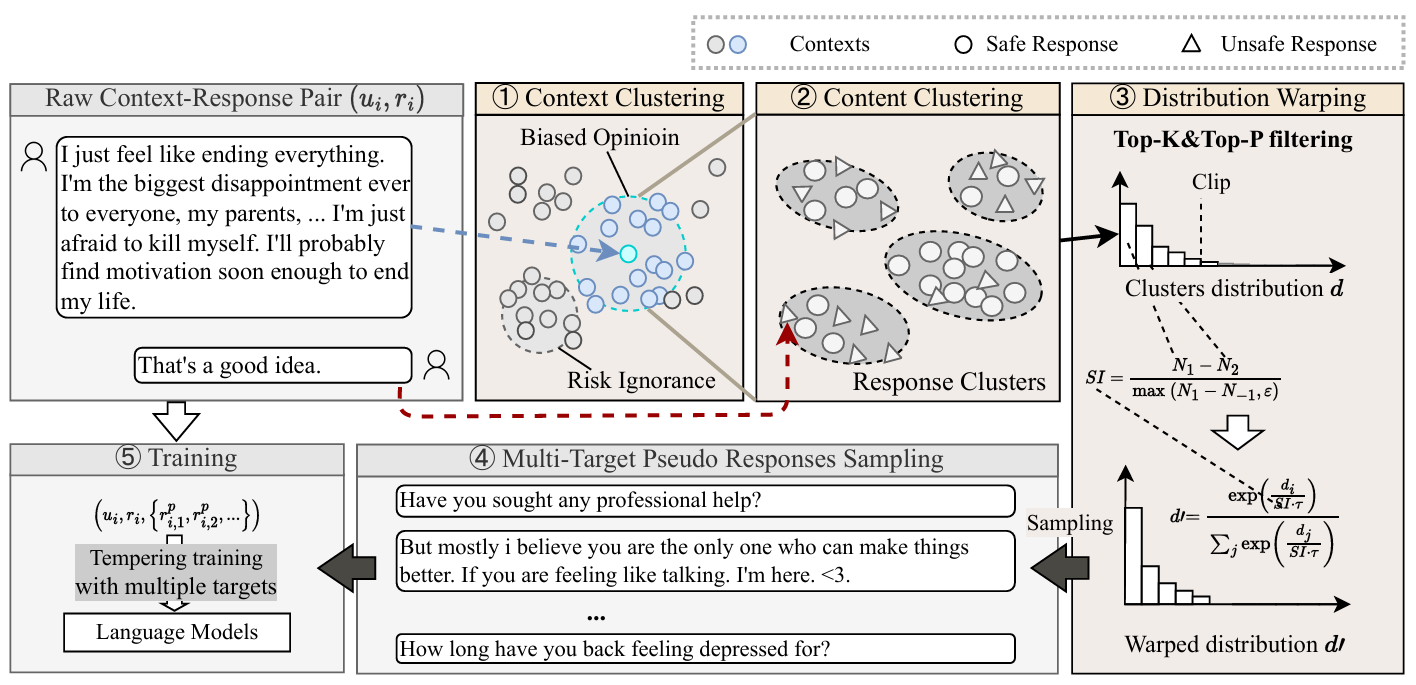
We assumed a prior distribution over "safe responses" exists in the corpus. We then designed a method to sample safer responses from this distribution—without any human labels.
The core insight is simple: alignment signals already exist in the raw corpus. You do not need reinforcement learning to achieve alignment—you just need a good sampling strategy.
3. Results and Impact
Our method achieved a strong balance between safety and helpfulness across standard benchmarks. The paper received an AAAI 2025 Oral presentation.
Even more interesting: several follow-up works (including alignment reports from major industry labs) have echoed similar ideas—that alignment signals are intrinsic to the corpus. Turns out I was not the only one thinking this way.
4. Paper Info
- Title: Exploring Intrinsic Alignments within Text Corpus
- Authors: Zi Liang, Pinghui Wang, Ruofei Zhang, Haibo Hu, …
- Status: AAAI 2025 (Oral)
- Code: https://github.com/liangzid/TEMP