中文预训练模型汇总
Table of Contents
1. 中文预训练模型汇总
1.1. 通用寻找方式,基于huggingface
1.1.1. 网址:https://huggingface.co/
下面以bert-base-chinese演示其使用方式。
1.1.2. 使用步骤
- 下载词汇表和配置文件
在下图所示的地方可以看见huggingface维护的整体的git仓库。
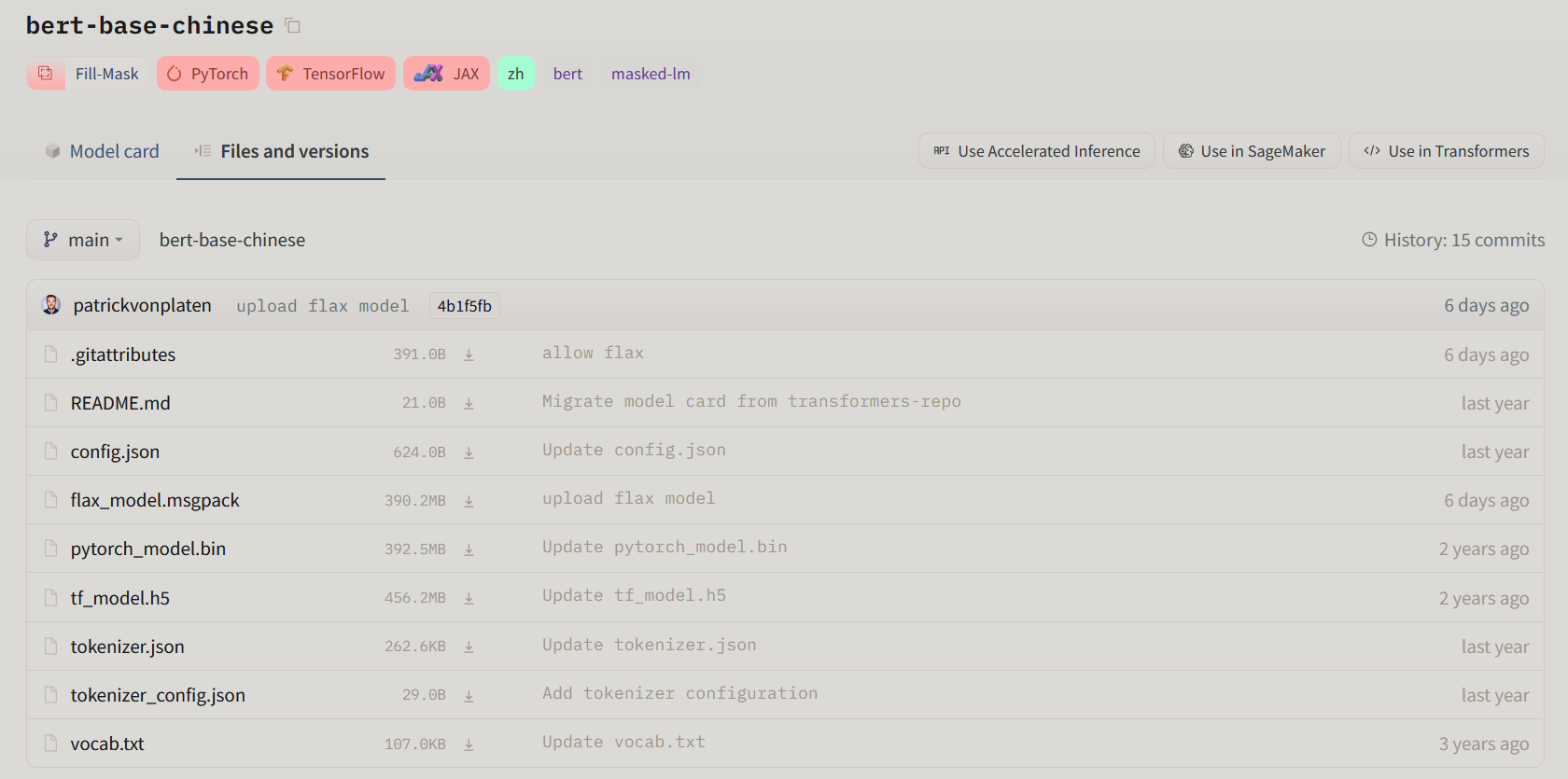
在Use in Transformers中进行导入操作
git clone https://huggingface.co/bert-base-chinese注意,如果没有lfs支持的话,这样无法下载pytorch_model.bin文件。
- 下载预训练模型库
可以在浏览器中通过点击,或者其他的一些方法,下载该二进制文件,然后覆盖到该目录之下。
- 加载模型的思路
- 加载tokenizer
不建议用自动加载,建议自己写一下加载方式,主要语法就是MoumouTokenizer.from_pretrained(dirpath)这种格式。注意记得添加自定义的特殊token
- 加载预训练模型
不建议自动加载,主要语法是MoumouXingshiModel.from_pretrained(dirpath)这种。
- 基于任务设置合理的模型
上述的预训练模型,可以被不同的类引用,如BERT,可能就可以用在句子分类、token分类、回归问题等等各种领域。 参考地址:https://huggingface.co/transformers/model_doc/bert.html
- 加载tokenizer
1.2. NLU模型
1.2.1. electra
挺多的,就推荐这个吧!感觉还不错。
地址: https://huggingface.co/hfl/chinese-electra-180g-small-discriminator
注意:在使用electra时,如果添加了额外的token,需要做一个resize,一个参考如下面代码所示:
model = ElectraForTokenClassification.from_pretrained(args.import_model_path, num_labels=102)
model.resize_token_embeddings(len(tokenizer))
此处的tokenizer为ElectraTokenizer。
类似的roberta都有这个问题。
1.3. NLG模型
1.3.1. GPT-2的各种资源
目前在使用的是github上一个xd的版本,感觉还挺好用的。
传送门:https://github.com/ghosthamlet/gpt2-ml-torch
代码都不用怎么看,预训练模型搞到手就可以了。